4. 페이지 빌드 및 확인 작업
지금까지 데이터베이스에 넣는 작업까지 노코기리 튜토리얼에서 살펴보았습니다.
그럼 이제, 실제로 레일즈로 페이지를 띄워서 우리가 얻은 자료들이 잘 추출되었는지 확인해 보겠습니다. 이 곳에 포스팅되는 내용은 루비온레일즈와 관련이 있으므로 자세한 설명은 생략하겠습니다.
먼저 라우터 설정으로 첫 페이지를 #index로 바꿔보겠습니다. /config/routes.rb/로 가서 #root 'welcome#index'의 주석을 풀고 root 'notices#index'로 루트 페이지를 조정합니다. 이유는 그냥 첫 페이지에 올린 내용을 바로 확인하고 싶어서 그렇습니다.
Rails.application.routes.draw do
resources :notices
root 'notices#index'
#이하 생략
이번에는 화면을 표시해줄 View을 살펴보겠습니다. Scaffold로 기본적인 클래스 및 메소드들이 모두 설정이 되어있고 Views도 모두 설정이 되어있습니다. 그래서 따로 조정하지 않겠습니다. 조금 멋이 없지만 지금은 크롤링 결과물 내용이 더 중요하므로 원래 있던 형태를 최대한 활용하겠습니다. 그럼 페이지를 빌드 해보겠습니다.
$ rails s
그리고 웹 브라우저에서 http://localhost:3000/로 들어가서 페이지를 확인합니다. 그럼 다음과 같은 화면이 나옵니다. 실제 동국대학교 학사 공지사항 1페이지와 비교해 보았을 때 일반 공지사항만 중복없이 잘 들어간 것을 확인할 수 있습니다.
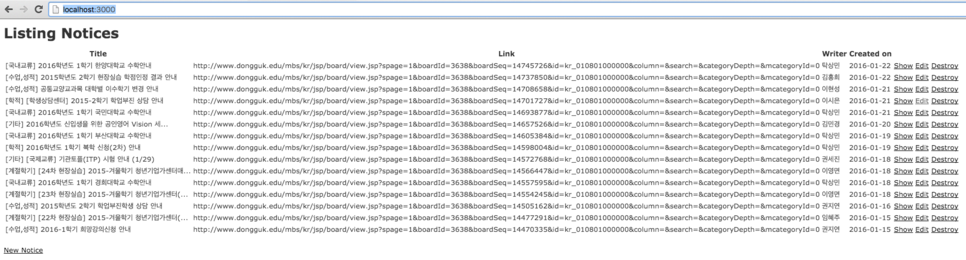 notice.rb 소스에서 DB에 직접 넣는 기능을 구현했기 때문에 모두 DB에 들어가 있습니다. 그리고 Scaffold 만들어서 새로 추가하거나 수정 및 삭제가 가능합니다.
notice.rb 소스에서 DB에 직접 넣는 기능을 구현했기 때문에 모두 DB에 들어가 있습니다. 그리고 Scaffold 만들어서 새로 추가하거나 수정 및 삭제가 가능합니다.
기본적으로 원하는 페이지를 선택하고 분석하여 가져오고 원하는 방식대로 바꿔서 활용하는 것까지 전체 내용을 전부 다루었습니다. 다른 방식으로 하는 방법도 있지만 큰 틀은 비슷하므로 개념을 익히고 넘어간다는 생각으로 접근하시는 것이 좋을 것 같습니다. 제가 처음 크롤링을 하고 싶었을 때 무작정 검색만하다가 포기를 했던 기억이 있습니다. 지금은 여러 공부를 병행하고 있는데 지금 생각해보면 그리 어렵지 않은 내용이었습니다. 다른 언어로도 마찬가지입니다. 이제부터는 크롤링을 하는 친구가 있다면, 대단하다면서 신기하게 보지만 말고 직접 할 수 있는 사람이 되었으면 좋겠습니다. 저와 똑같은 삽질은 더이상 하지 않게 하고 싶어서 이 글을 썼습니다. 이렇게 노코기리로 웹 스크래핑하기 튜토리얼을 마칩니다. 이 다음 챕터부터는 추가적인 이슈나 다른 예제를 만들었을 때 추가하겠습니다.
감사합니다.