3. 페이지 분석하기
이번에는 수집 대상 페이지를 분석하는 작업을 진행할겁니다. 여기서 예시로 사용할 페이지는 동국대학교 공식 홈페이지의 공지사항입니다. 우선 동국대학교 홈페이지(http://www.dongguk.edu/mbs/kr/index.jsp)에 접속해 봅시다. 주소를 잠깐 살펴보면 끝이 (.jsp)라고 되어있죠? 이 말은 이 페이지가 JSP를 사용하여 만들어졌다는 걸 암시합니다. 그냥 참고로 알아두세요.
그럼 다음과 같은 페이지가 나옵니다. 첫 페이지에 크게 7개의 카테고리로 공지사항을 제공하고 있는 걸 확인할 수 있습니다. 각각의 페이지들을 살펴보면 구조가 같고 URL과 내용만 다르기때문에 저는 '학사' 페이지를 분석을 해보겠습니다.
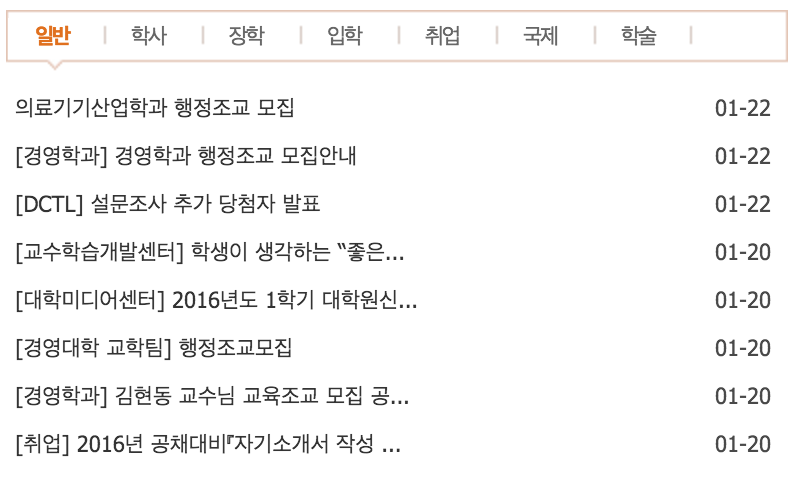
대상 페이지의 URL 분석하기
대상 페이지가 하나라면 상관없지만 2~100 페이지를 분석하려고 한다면 여러 페이지에 접속해야겠죠?
우선 학사 페이지를 클릭해서 들어가 봅시다. 첫 페이지의 URL을 보면 다음과 같습니다.
- "www.dongguk.edu/mbs/kr/jsp/board/list.jsp?boardId=3638&id=kr_010801000000”
그렇다면 다음 페이지는 어떻까요?
- "생략...&command=list&id=kr_010801000000&mcategoryId=0&spage=2”
동국대학교 정도의 학교 공식 홈페이지가 이상하군요. URL이 페이지 하나 달라졌다고 이렇게 달라지면 어쩌라구요? 괜찮습니다. 첫 페이지는 짧게 표시가 되지만, 페이지네이션하는 방식에 따라 URL이 다르게 표현될 수 있는 겁니다. 여러 URL이 사실 하나의 같은 페이지로 향하고 있다면 이해가 가는 부분입니다. 이걸 증명하려면 현재 상황에서 다시 1페이지를 클릭해서 돌아가면 확인이 가능합니다.
- "생략...&command=list&id=kr_010801000000&mcategoryId=0&spage=1"
다시 길지만 끝 부분이 "space=1"이 된 걸 확인하실 수 있습니다. 그렇다면 3 페이지로 가려면 끝 부분을 3으로 바꿔주면 되겠다는 생각이 드시나요? 안 든다면, HTTP 프로토콜 개념에 대해서 공부하고 오시는 걸 추천합니다. 이런 방법으로 우리는 N 페이지에 URL GET Request 방식으로 접근할 수 있다는 지식을 얻었습니다.
추출하려는 데이터 구조 설계하기
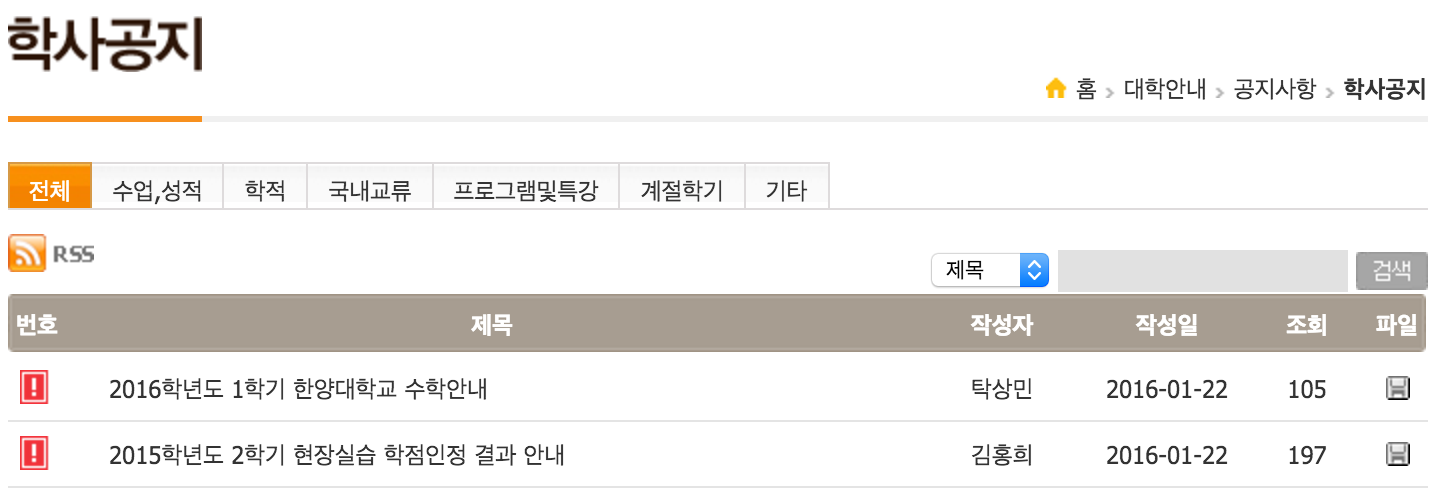
위 화면을 살펴보면 공지사항이라는 게시판에서 추출할 수 있는 데이터 목록이 크게 몇 가지로 추려지는 걸 알 수 있습니다. '번호', '제목', '작성자', '작성일', '조회', '파일' 총 6개로 나누어 볼 수 있습니다.
하지만 우리는 좀 다르게 보고 4개만 선정해보겠습니다.
- 제목
- 제목에 연결되어 있는 링크(URL)
- 작성자
- 작성일
어라? 6개에는 링크는 없는데 어떻게 추출할까요? 다 방법이 있습니다. 바로 페이지 소스 파일에서 그 정보를 얻을 수 있습니다. 페이지 소스는 해당 페이지에서 우클릭 후 '페이지 소스보기' 또는 '검사'를 통해서 확인 가능합니다.
추출 대상 페이지 분석하기
그런데 시작하기도 전에 문제가 하나 발생합니다. 다음 사진을 자세히 보세요.


두 공지는 같은 페이지에 존재하는 두 글입니다. 하지만 사실상 같은 글이죠. 클릭을 하면 같은 페이지로 이동합니다. 게시판을 보는 입장에서는 그냥 '!' 표시를 하면서 중요 공지 표시를 하려는구나 하고 넘어가면 되지만 이걸 구현하는 개발자 입장에서는 골치아픈 요소 중 하나입니다. 페이지 소스를 열어봐도 역시나 저 두 글이 모두 나와있고 테이블 구조도 비슷해 보입니다. 만약 이대로 진행을 해버리면 DB에서 [국내교류] 라는 것 스트링 차이때문에 다른 글로 인식하고 중복된 데이터가 들어가게 됩니다. 물론 둘 다 수집할 필요가 있다면 상관없지만 우선은 중복이 되면 안된다고 가정하고 진행해보겠습니다. 분명 소스 상에는 이 두 글의 차이가 있을 겁니다.
자세히 살펴보면 두 글의 차이는... 하나는 '!' 표시가 있고 글 번호가 없습니다. 반면에 다른 하나는 글 번호가 4472. 그리고 [국내교류]가 맨 앞에 붙어있고 우측에 새로운 글 'N' 표시도 있습니다. 이 걸로 구분을 하면 될 것 같습니다. 그럼 이러한 차이점을 염두해두고 소스 파일을 살펴보겠습니다. 다시 한번 우클릭 후 페이지 소스파일로 이동합니다.
<html xmins="http://www.w3.org/1999/xhtml">
<head>...</head>
<body>
<ul>...</ul>
<div>...</div>
...
<table id="board_list" summary="...">
<colgroup>...</colgroup>
<thead>...</thead>
<tbody>
</tbody>
...
전부 가져올 수 없기 때문에 큰 구조만 가져왔습니다. 뭐 대충 이런식으로 시작합니다. 하지만 추출하고 싶은 내용들은 안에 있었습니다. 그렇다면 우리가 접근해야할 가장 첫 번째 위치는 입니다. 감사하게도 해당 페이지 소스에서 는 단 하나밖에 없습니다. 그러므로 를 찾으라는 명령을 내리면 바로 우리가 원하는 위치로 갈 수 있다는 겁니다. 이런식으로 처음에 할 일은 원하는 내용의 위치를 파악하는 일입니다. 그리고 세부적으로 분석해 나아가는 거죠. 이제는 안의 내용을 살펴봅시다. 우선은 '!'이 표시가 되어있는 알림 공지부터 살펴보겠습니다.
<tr>
<td>
<img src="..." alt title="공지">
</td>
<td class="title">
<a href="url주소">2016학년도 1학기 한양대학교 수학안내</a>
</td>
<td>탁상민</td>
<td>2016-01-22</td>
<td>105</td>
<td>
<img src="..." alt="파일">
</td>
</tr>
처음에 '!' 표시는 이미지 태그로 그리고 첨부된 파일도 이미지 태그로 표시되어 있습니다. 단순한 문자가 아니었네요? 참고로 첨부된 파일이 없을 때에는 그냥 "-" 이렇게 표시가 되어 있습니다. 다시 언급하지만 알림 공지('!')는 중복 데이터이므로 수집하면 안됩니다. 이번에는 일반적인 공지의 구조를 살펴보겠습니다.
<tr>
<td>4472</td>
<td class="title">
<a href="url주소">2016학년도 1학기 한양대학교 수학안내</a>
<img src="..." alt="N" title="새글">
</td>
<td>탁상민</td>
<td>2016-01-22</td>
<td>105</td>
<td>
<img src="..." alt="파일">
</td>
</tr>
위에서 살펴 보았듯이 두 글에는 몇 가지 차이가 있습니다. 방법은 여러가지가 있겠지만, 여기서 저는 첫 번째 에 있는 값의 형태로 구분을 해보겠습니다. 추출 대상이 되는 글은 글 번호로 시작합니다. 그리고 나머지를 분석한 결과를 한글로 풀어쓰면 다음과 같습니다.
- 제목 : title 클래스(class="title")가 있는 td 태그 안의 a 태그 속 텍스트
- 링크 : title 클래스(class="title")가 있는 td 태그 안의 a 태그안의 href에 할당된 텍스트
- 작성자 : tr 태그 안에서 세 번째 td 태그 안에 있는 텍스트
- 작성일 : tr 태그 안에서 네 번째 td 태그 안에 있는 텍스트
이렇게 페이지 분석이 끝났습니다. 이 걸 가져오겠다! 마음만 먹은 걸로 충분합니다. 이제 "무엇을?"은 끝났으니 "어떻게?"를 살펴 보겠습니다. 본격적으로 'Nokogiri gem'을 이용하여 정보를 수집하는 방법에 대해서 알아보겠습니다.